###排查资源使用情况:
一般云计算平台或者传统的 IDC 主机都会有相应的监控平台
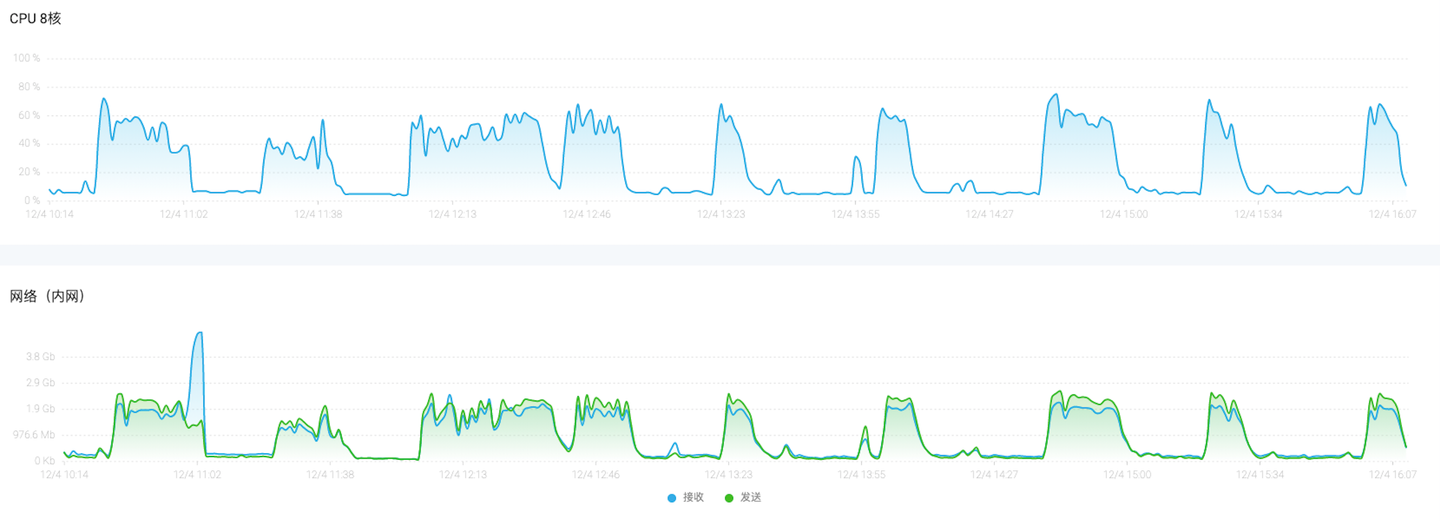
通过分析历史的 CPU 、MEM、磁盘 IO、带宽大小等数值分析是不是因为资源占用异常导致的系统重启
或者登录机器
- 通过 free 命令查看内存信息
$free
total used free shared buff/cache available
Mem: 3880172 187996 1974484 544 1717692 3407556
Swap: 0 0 0- top 命令查看占用较高内存 CPU 的进程有无异常
$top - 18:17:43 up 26 days, 7:19, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 94 total, 1 running, 93 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880172 total, 1973048 free, 189016 used, 1718108 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3406504 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 43576 3964 2580 S 0.0 0.1 1:26.70 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.68 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:04.58 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 0:07.54 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 2:26.47 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0.0 0.0 0:06.27 watchdog/0
12 root rt 0 0 0 0 S 0.0 0.0 0:05.24 watchdog/1
13 root rt 0 0 0 0 S 0.0 0.0 0:07.68 migration/1
14 root 20 0 0 0 0 S 0.0 0.0 0:04.44 ksoftirqd/1
16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/1:0H
18 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
19 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns
20 root 20 0 0 0 0 S 0.0 0.0 0:00.48 khungtaskd
21 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 writeback
22 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kintegrityd
23 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
24 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
25 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
26 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kblockd- 通过 netstat -ant | awk ‘{split($5, arr, “:”); print arr[1]}’ | sort | uniq -c |sort -nr | head 命令查看建立连接数
$netstat -ant | awk '{split($5, arr, ":"); print arr[1]}' | sort | uniq -c |sort -nr | head
12 0.0.0.0
10 58.33.27.210
7 180.164.153.113
1 169.254.0.55通过 iostat vmstat 或 lsof 查看系统盘的 IO 情况, 找到异常读写的进程
###通过 linux 系统日志排查
系统日志通常在 /var/log 下:
/var/log/message 记录Linux操作系统常见的系统和服务错误信息
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 永久记录每个用户登录、注销及系统的启动、停机的事件
/var/run/utmp 记录当前正在登录系统的用户信息;
/var/log/btmp 记录失败的登录尝试信息。- 通常我们主要分析操作系统日志 /var/log/message
执行 grep -E -i -r “panic|error|exception|shutdown” /var/log/message
看看得到的信息是否有异常的情况
例如出现下面类似的日志说明有人通过控制台或者电源键进行了关机
Mar 01 23:12:34 hostname shutdown: shutting down for system halt还可以通过 grep -iv ‘: starting|kernel: .: Power Button|watching system buttons|Stopped Cleaning Up|Started Crash recovery kernel’ \ /var/log/messages /var/log/syslog /var/log/apcupsd \ | grep -iw ‘recover[a-z]*|power[a-z]*|shut[a-z ]*down|rsyslogd|ups’ 得到更多相关的日志
当发生意外断电或者硬件故障的时候,文件系统不会被正常的卸载所以下次主机启动的时候你会看到类似下面的日志:
EXT4-fs ... INFO: recovery required ...
Starting XFS recovery filesystem ...
systemd-fsck: ... recovering journal
systemd-journald: File /var/log/journal/.../system.journal corrupted or uncleanly shut down, renaming and replacing.当用户通过电源键进行关机时会得到下面类似的日志:
systemd-logind: Power key pressed.
systemd-logind: Powering Off...
systemd-logind: System is powering down.###主机重启历史和登录情况分析
通过* last reboot* 查看最近系统重启的信息:第一行个时间是重启时间-8 第二个是当前时间
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 21:56 - 14:40 (-7:-15)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 21:49 - 14:40 (-7:-8)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 21:41 - 14:40 (-7:00)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 21:25 - 14:40 (-6:-44)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 21:15 - 14:40 (-6:-34)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 20:57 - 14:40 (-6:-16)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 20:53 - 14:40 (-6:-13)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 20:49 - 14:40 (-6:-8)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 20:39 - 14:40 (-5:-58)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 18:41 - 14:40 (-4:00)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 17:57 - 14:40 (-3:-16)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 17:23 - 14:40 (-2:-42)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 17:11 - 14:40 (-2:-30)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 16:54 - 14:40 (-2:-13)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 16:27 - 14:40 (-1:-46)
reboot system boot 3.10.0-957.5.1.e Fri Dec 4 15:44 - 14:40 (-1:-3)last 命令参数说明:
-a 将登录系统的主机名称或IP地址,显示在最后一行
-d 将IP地址转换成主机名称
-f 指定记录文件,默认是显示/var/log目录下的wtmp文件的记录,但/var/log目录下得btmp能显示的内容更丰富,可以显示远程登录,例如ssh登录 ,包括失败的登录请求。
-i 显示特定ip登录的情况。跟踪用
-o Read an old-type wtmp file (written by linux-libc5 applications).
-n <显示列数>或-<显示列数> 设置列出名单的显示列数
-w Display full user and domain names in the output
-R 不显示登入系统的主机名称或IP(省略 hostname 的栏位)
-t 显示YYYYMMDDHHMMSS之前的信息
-x 显示系统关闭、用户登录和退出的历史通过 last -n 5 -a -i 排查最近异常登录情况, 排除入侵问题
root pts/5 Fri Dec 4 14:42 still logged in 58.33.27.210
root pts/3 Fri Dec 4 14:38 still logged in 58.33.27.210
root pts/3 Fri Dec 4 14:23 - 14:23 (00:00) 123.123.6.205
root pts/4 Fri Dec 4 14:12 - 14:43 (00:31) 192.168.0.67
root pts/3 Fri Dec 4 14:08 - 14:20 (00:12) 1.202.240.26结合 Kdump 和 crash 工具排查
- Kdump
kdump是一种kernel crash dump的机制,它可以在内核crash时保存系统的内存信息用于后续的分析。kdump是基于kexec的。
crash是一个用于交互式地分析正在运行的Linux系统或者kernel crash后的core dump数据的工具。
dump的工作原理图:


- crash
crash是redhat的工程师开发的,主要用来离线分析linux内核转存文件,它整合了gdb工具,功能非常强大。可以查看堆栈,dmesg日志,内核数据结构,反汇编等等。crash支持多种工具生成的转存文件格式,如kdump,LKCD,netdump和diskdump,而且还可以分析虚拟机Xen和Kvm上生成的内核转存文件。同时crash还可以调试运行时系统,直接运行crash即可,ubuntu下内核映象存放在/proc/kcore。
使用这两个工具来排除异常重启问题必须符合后续还会继续发生异常重启的情况,这个时候我们通过
kdump 工具保存内核在crash时的系统内存信息用于后续的分析;kdump 默认会在/var/crash/ 目录下保存生成的crash 信息
通过crash 命令分析
crash /usr/lib/debug/lib/modules/xxx/vmlinux /var/crash/xxx/vmcore使用 crash 调试转储文件,需要在命令行输入两个参数:debug kernel 和 dump file,其中 dump file 是内核 crash 时生成的 dump 文件的名称,debug kernel 是由内核调试信息包安装的,不同的发行版名称略有不同,以 RHEL为例:
debug kernel 文件需要额外安装 kernel-debuginfo 才会有
通常我们使用 yum 进行安装
yum install http://debuginfo.centos.org/7/x86_64/kernel-debuginfo-common-x86_64-3.10.0-957.10.1.el7.x86_64.rpm yum install http://debuginfo.centos.org/7/x86_64/kernel-debuginfo-3.10.0-957.10.1.el7.x86_64.rpm$crash /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux /var/crash/127.0.0.1-2019-07-21-17\:07\:17/vmcore执行命令后可以看到 crash 工具分析报告的摘要
crash 7.1.5-2.el7
Copyright (C) 2002-2016 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006, 2010 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006, 2011, 2012 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005, 2011 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under certain conditions.
Enter "help copying" to see the conditions. This program has absolutely no warranty. Enter "help warranty" for details. GNU gdb (GDB) 7.6 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-unknown-linux-gnu"...
KERNEL: /usr/lib/debug/lib/modules/3.10.0-514.el7.x86_64/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2019-07-21-17:07:17/vmcore [PARTIAL DUMP]
CPUS: 56
DATE: Sun Jul 21 17:07:00 2019
UPTIME: 8 days, 03:43:48
LOAD AVERAGE: 1.98, 1.73, 1.73
TASKS: 4444
NODENAME: hyhive
RELEASE: 3.10.0-514.el7.x86_64
VERSION: #1 SMP Tue Nov 22 16:42:41 UTC 2016
MACHINE: x86_64 (2600 Mhz)
MEMORY: 255.9 GB
PANIC: "BUG: unable to handle kernel paging request at ffff8800fc14dfb0"
PID: 21793
COMMAND: "sh"
TASK: ffff883f97751f60 [THREAD_INFO: ffff8830e1b50000]
CPU: 49
STATE: TASK_RUNNING (PANIC)
crash>在 crash 工具内我们可以输入 help 看到所有 crash 的子命令
crash> help
* files mach repeat timer alias foreach mod runq tree ascii fuser mount search union bt gdb net set vm btop help p sig vtop dev ipcs ps struct waitq dis irq pte swap whatis eval kmem ptob sym wr exit list ptov sys q extend log rd task
crash version: 7.1.9-2 gdb version: 7.6
For help on any command above, enter "help <command>".
For help on input options, enter "help input".
For help on output options, enter "help output".例如:
bt显示内核堆栈跟踪
crash> bt
PID: 3320 TASK: ffff88017092dee0 CPU: 0 COMMAND: "qemu-kvm-2.6"
#0 [ffff88007b2aba48] machine_kexec at ffffffff8105c4cb
#1 [ffff88007b2abaa8] __crash_kexec at ffffffff81104a32
#2 [ffff88007b2abb78] crash_kexec at ffffffff81104b20
#3 [ffff88007b2abb90] oops_end at ffffffff816880f8
#4 [ffff88007b2abbb8] no_context at ffffffff8167829a
#5 [ffff88007b2abc08] __bad_area_nosemaphore at ffffffff81678330
#6 [ffff88007b2abc50] bad_area_nosemaphore at ffffffff8167849a
#7 [ffff88007b2abc60] __do_page_fault at ffffffff8168afbe
#8 [ffff88007b2abcc0] do_page_fault at ffffffff8168b165
#9 [ffff88007b2abcf0] page_fault at ffffffff81687388
[exception RIP: unknown or invalid address]
RIP: 00007ffd81487700 RSP: ffff88007b2abda0 RFLAGS: 00010002
RAX: ffff880175733e38 RBX: 0000000075733f28 RCX: 0000000000000000
RDX: 0000000000000000 RSI: 0000000000000003 RDI: ffff880175733e38
RBP: ffff88007b2abde0 R8: 0000000000000000 R9: 0000000000000000
R10: 00000000000103c0 R11: 0000000000000293 R12: ffffffff81a93648
R13: 000055deb2c80ef8 R14: 0000000000000000 R15: 0000000000000003
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#10 [ffff88007b2abda0] __wake_up_common at ffffffff810ba588
#11 [ffff88007b2abde8] __wake_up at ffffffff810bd4f9
#12 [ffff88007b2abe20] __vga_put at ffffffff8143535e
#13 [ffff88007b2abe48] vga_put at ffffffff814356ff
#14 [ffff88007b2abe70] vfio_pci_vga_rw at ffffffffc04a8e54 [vfio_pci]
#15 [ffff88007b2abed0] vfio_pci_rw at ffffffffc04a55c1 [vfio_pci]
#16 [ffff88007b2abee0] vfio_pci_read at ffffffffc04a594c [vfio_pci]
#17 [ffff88007b2abef0] vfio_device_fops_read at ffffffffc048b233 [vfio]
#18 [ffff88007b2abf00] vfs_read at ffffffff81200b9c
#19 [ffff88007b2abf30] sys_pread64 at ffffffff81201c32
#20 [ffff88007b2abf80] system_call_fastpath at ffffffff8168fe49
RIP: 00007feac42e1fc3 RSP: 00007feab9b6b908 RFLAGS: 00000206
RAX: 0000000000000011 RBX: ffffffff8168fe49 RCX: 0000000000000025
RDX: 0000000000000001 RSI: 00007feab9b6b700 RDI: 000000000000002b
RBP: 0000000000000001 R8: 0000000000000008 R9: 00000000000000ff
R10: 00000800000003da R11: 0000000000000293 R12: 0000000000000000
R13: 000000000000001a R14: 0000000000000001 R15: 0000559178fb02b0
ORIG_RAX: 0000000000000011 CS: 0033 SS: 002bps显示系统中进程的状态
Textcrash> ps | grep RU 0 0 0 ffffffff819c9480 RU 0.0 0 0 [swapper/0] 0 0 1 ffff880177609fa0 RU 0.0 0 0 [swapper/1] > 0 0 2 ffff88017760af70 RU 0.0 0 0 [swapper/2] 0 0 3 ffff88017760bf40 RU 0.0 0 0 [swapper/3] > 1889 1880 3 ffff8801727b3f40 RU 0.3 386192 21456 X > 3320 3200 0 ffff88017092dee0 RU 47.7 3914004 2986980 qemu-kvm-2.6 > 3652 1879 1 ffff880053795ee0 RU 0.0 106640 2640 qemu-img crash> ps | grep 3200 2276 1914 0 ffff880063320000 IN 0.0 784512 3096 gmain 3200 1879 1 ffff880174086eb0 IN 0.0 76728 1792 uniqb-runtime 3311 3200 1 ffff88017705cf10 IN 47.7 3914004 2986980 qemu-kvm-2.6 3316 3200 1 ffff88004f888fd0 IN 47.7 3914004 2986980 qemu-kvm-2.6 3319 3200 0 ffff88004f88bf40 IN 47.7 3914004 2986980 qemu-kvm-2.6 > 3320 3200 0 ffff88017092dee0 RU 47.7 3914004 2986980 qemu-kvm-2.6 3321 3200 3 ffff88017092af70 IN 47.7 3914004 2986980 qemu-kvm-2.6 3322 3200 1 ffff880170929fa0 IN 47.7 3914004 2986980 qemu-kvm-2.6 3323 3200 0 ffff88017092cf10 IN 47.7 3914004 2986980 qemu-kvm-2.6 3325 3200 3 ffff8800631d2f70 IN 47.7 3914004 2986980 qemu-kvm-2.6 3331 3200 0 ffff8801745daf70 IN 47.7 3914004 2986980 threaded-ml 3333 3200 3 ffff88004f88af70 IN 47.7 3914004 2986980 qemu-kvm-2.6 3334 3200 2 ffff880174082f70 IN 47.7 3914004 2986980 qemu-kvm-2.6 3337 3200 2 ffff880174080fd0 IN 47.7 3914004 2986980 qemu-kvm-2.6 3651 3200 3 ffff880077a30fd0 UN 0.0 142040 1680 sum
vm显示当前上下文的虚拟内存信息
通过分析 crash 中的异常进程和堆栈信息可以更进一步发现异常重启的真正原因



